6-28 2,795 views
1 摘要
Kylin作为MOLAP的代表之一,其核心思想是设计cube模型,指定维度和量度,通过在维度上进行量度的预先上卷计算,保存上卷结果,以空间换时间,加速维度聚合查询。因此,预算计算这一构建流程是Kylin的核心之一,下面分构建调度和构建执行三个部分介绍一下Kylin构建原理。
2 构建调度
Kylin构建可通过REST API触发,地址是“/{cubeName}/build”。发起任务构建时,首先通过server-base中JobService的submitJobInternal方法提交任务,该方法通过调用core-job中EngineFactory的createBatchCubingJob方法完成任务创建。在创建任务时,首先根据CubeSegment的getEngineType获取引擎类型,然后根据不同类型获取相应的引擎实例。Kylin目前支持以下类型的构建引擎:
- apache.kylin.engine.mr.MRBatchCubingEngine,engineType=0;
- apache.kylin.engine.mr.MRBatchCubingEngine2,engineType=2;
- apache.kylin.engine.spark.SparkBatchCubingEngine2,engineType=4;
- apache.kylin.engine.flink.FlinkBatchCubingEngine2,engineType=5;
这些引擎均实现了IBatchCubingEngine,从命名可以看出分别采用MapReduce、Spark、Flink进行构建,开发者也可以实现其他方式的构建引擎,并通过在配置中增加“kylin.engine.provider.type值=实现类”项引入。
构建引擎的执行逻辑后面会详细介绍。这里createBatchCubingJob方法返回DefaultChainedExecutable类实例,该类继承自AbstractExecutale类,表示一个可执行的任务,同时还维护包含多个子任务的链表。AbstractExecutable实现了Executable接口,在execute方法中实现了重试机制,而把具体的执行逻辑通过抽象方法doWork委托给子类实现,而在DefaultChainedExecutable类中,doWork方法遍历子任务链表,逐一执行子任务的execute方法。
在获取DefaultChainedExecutable类实例后,通过调用ExecutableManager类的addJob进行持久化。持久化的实现机制已在元数据源码分析部分介绍。持久化的key格式是“/execute/uuid”。
在持久化任务后,Kylin server作为构建节点,其构建逻辑入口在server-base的JobService中。该类的afterPropertiesSet方法会初始化Scheduler接口实例,根据配置项“kylin.job.scheduler.default”(默认值为0)从SchedulerFactory获取相应的Scheduler接口实现示例。Scheduler用于任务调度,其实现有:
- apache.kylin.job.impl.threadpool.DefaultScheduler,schedulerType=0;
- apache.kylin.job.impl.threadpool.DistributedScheduler,schedulerType=2;
- apache.kylin.job.impl.threadpool. NoopScheduler,schedulerType=77;
开发者也可以实现其他方式的调度器,并通过在配置中增加“kylin.job.scheduler.provider.type值=实现类”项引入。
Kylin默认使用DefaultScheduler,应用于Kylin server以单节点方式部署这一场景下。如果Kylin server是多节点部署,则需要通过“kylin.job.scheduler.default=2”使用DistributedScheduler。DistributedScheduler的逻辑和DefaultScheduler类似,主要区别是在调度任务时,会尝试获取该任务的分布式锁,只有获取到锁的情况下,才会继续执行,避免分布式场景下的并发问题,而分布式锁是基于Zookeeper的临时节点实现的。
DefaultScheduler调度任务的核心逻辑如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
@Override public synchronized void init(JobEngineConfig jobEngineConfig, JobLock lock) throws SchedulerException { jobLock = lock; // 只有服务器模式是job或all的,才会负责执行构建任务,进行相关初始化 String serverMode = jobEngineConfig.getConfig().getServerMode(); if (!("job".equals(serverMode.toLowerCase(Locale.ROOT)) || "all".equals(serverMode.toLowerCase(Locale.ROOT)))) { logger.info("server mode: " + serverMode + ", no need to run job scheduler"); return; } logger.info("Initializing Job Engine ...."); if (!initialized) { initialized = true; } else { return; } this.jobEngineConfig = jobEngineConfig; if (jobLock.lockJobEngine() == false) { throw new IllegalStateException("Cannot start job scheduler due to lack of job lock"); } // 创建定时调度线程池,用于从持久化存储中加载任务 //load all executable, set them to a consistent status fetcherPool = Executors.newScheduledThreadPool(1); int corePoolSize = jobEngineConfig.getMaxConcurrentJobLimit(); // 从配置中获取任务并行度设置,并创建相应线程数的线程池用于执行任务 jobPool = new ThreadPoolExecutor(corePoolSize, corePoolSize, Long.MAX_VALUE, TimeUnit.DAYS, new SynchronousQueue<Runnable>()); context = new DefaultContext(Maps.<String, Executable> newConcurrentMap(), jobEngineConfig.getConfig()); logger.info("Starting resume all running jobs."); // 获取ExecutableManager ExecutableManager executableManager = getExecutableManager(); executableManager.resumeAllRunningJobs(); logger.info("Finishing resume all running jobs."); int pollSecond = jobEngineConfig.getPollIntervalSecond(); logger.info("Fetching jobs every {} seconds", pollSecond); JobExecutor jobExecutor = new JobExecutor() { @Override public void execute(AbstractExecutable executable) { jobPool.execute(new JobRunner(executable)); } }; // 根据配置创建FetchRunner,支持两种FetchRunner,分配按照优先级或默认序加载任务 fetcher = jobEngineConfig.getJobPriorityConsidered() ? new PriorityFetcherRunner(jobEngineConfig, context, jobExecutor) : new DefaultFetcherRunner(jobEngineConfig, context, jobExecutor); logger.info("Creating fetcher pool instance:" + System.identityHashCode(fetcher)); fetcherPool.scheduleAtFixedRate(fetcher, pollSecond / 10, pollSecond, TimeUnit.SECONDS); hasStarted = true; } |
其中FetcherRunner定时从持久化存储中加载任务,并加入jobPool线程池中执行。
3 构建执行
上一节讲到Kylin支持多种构建引擎,但不管哪种构建引擎,其构建流程基本一致,包含以下几步:
- 根据数据模型将Hive中的事实表和维度表关联,创建中间宽表;
- 对中间宽表进行统计,并对部分字段创建字典,便于后续加速查询;
- 根据cube定义,基于中间宽表和字典,构建cube;
- 创建HTable,并将构建好的cube数据转化为HFile,并加载到HBase中;
- 更新cube状态,使构建后的数据生效;
下面主要介绍一下以Spark作为构建引擎的执行流程,该执行流程的任务编排在SparkBatchCubingJobBuilder2中,分析其源码主要包括以下几步:
- 创建中间宽表;
- 填充中间宽表;
- 从表中提取列值进行统计;
- 基于Spark构建字典;
- 保存cuboid统计信息;
- 创建HTable;
- 基于Spark构建cube;
- 转化cuboid数据至HFile;
- 加载HFile至HBase表;
- 更新cube信息;
- 清理Hive;
- 清理HDFS;
下面分别介绍一下这几步。
3.1 创建中间宽表
这一步的任务类是CreateFlatHiveTableStep。如果上游数据源是Hive(Kylin也支持Kafka等其他数据源),则生成中间宽表的drop和create语句并执行,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
DROP TABLE IF EXISTS kylin_intermediate_kylin_sales_cube_0e569fed_41a8_68f7_8c40_de478c9e4b04; CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_kylin_sales_cube_0e569fed_41a8_68f7_8c40_de478c9e4b04 ( `KYLIN_SALES_TRANS_ID` bigint ,`KYLIN_SALES_PART_DT` date ,`KYLIN_SALES_LEAF_CATEG_ID` bigint ,`KYLIN_SALES_LSTG_SITE_ID` int ,`KYLIN_CATEGORY_GROUPINGS_META_CATEG_NAME` string ,`KYLIN_CATEGORY_GROUPINGS_CATEG_LVL2_NAME` string ,`KYLIN_CATEGORY_GROUPINGS_CATEG_LVL3_NAME` string ,`KYLIN_SALES_LSTG_FORMAT_NAME` string ,`KYLIN_SALES_SELLER_ID` bigint ,`KYLIN_SALES_BUYER_ID` bigint ,`BUYER_ACCOUNT_ACCOUNT_BUYER_LEVEL` int ,`SELLER_ACCOUNT_ACCOUNT_SELLER_LEVEL` int ,`BUYER_ACCOUNT_ACCOUNT_COUNTRY` string ,`SELLER_ACCOUNT_ACCOUNT_COUNTRY` string ,`BUYER_COUNTRY_NAME` string ,`SELLER_COUNTRY_NAME` string ,`KYLIN_SALES_OPS_USER_ID` string ,`KYLIN_SALES_OPS_REGION` string ,`KYLIN_SALES_PRICE` decimal(19,4) ) STORED AS SEQUENCEFILE LOCATION 'xxx'; ALTER TABLE kylin_intermediate_kylin_sales_cube_0e569fed_41a8_68f7_8c40_de478c9e4b04 SET TBLPROPERTIES('auto.purge'='true'); |
其字段是在定义数据模型时所设置的字段。
3.2 填充中间宽表
这一步的任务类是RedistributeFlatHiveTableStep。将Hive中的事实表和维度表关联,并将数据插入到中间宽表中,其insert语句如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
INSERT OVERWRITE TABLE `kylin_intermediate_kylin_sales_cube_0e569fed_41a8_68f7_8c40_de478c9e4b04` SELECT `KYLIN_SALES`.`TRANS_ID` as `KYLIN_SALES_TRANS_ID` ,`KYLIN_SALES`.`PART_DT` as `KYLIN_SALES_PART_DT` ,`KYLIN_SALES`.`LEAF_CATEG_ID` as `KYLIN_SALES_LEAF_CATEG_ID` ,`KYLIN_SALES`.`LSTG_SITE_ID` as `KYLIN_SALES_LSTG_SITE_ID` ,`KYLIN_CATEGORY_GROUPINGS`.`META_CATEG_NAME` as `KYLIN_CATEGORY_GROUPINGS_META_CATEG_NAME` ,`KYLIN_CATEGORY_GROUPINGS`.`CATEG_LVL2_NAME` as `KYLIN_CATEGORY_GROUPINGS_CATEG_LVL2_NAME` ,`KYLIN_CATEGORY_GROUPINGS`.`CATEG_LVL3_NAME` as `KYLIN_CATEGORY_GROUPINGS_CATEG_LVL3_NAME` ,`KYLIN_SALES`.`LSTG_FORMAT_NAME` as `KYLIN_SALES_LSTG_FORMAT_NAME` ,`KYLIN_SALES`.`SELLER_ID` as `KYLIN_SALES_SELLER_ID` ,`KYLIN_SALES`.`BUYER_ID` as `KYLIN_SALES_BUYER_ID` ,`BUYER_ACCOUNT`.`ACCOUNT_BUYER_LEVEL` as `BUYER_ACCOUNT_ACCOUNT_BUYER_LEVEL` ,`SELLER_ACCOUNT`.`ACCOUNT_SELLER_LEVEL` as `SELLER_ACCOUNT_ACCOUNT_SELLER_LEVEL` ,`BUYER_ACCOUNT`.`ACCOUNT_COUNTRY` as `BUYER_ACCOUNT_ACCOUNT_COUNTRY` ,`SELLER_ACCOUNT`.`ACCOUNT_COUNTRY` as `SELLER_ACCOUNT_ACCOUNT_COUNTRY` ,`BUYER_COUNTRY`.`NAME` as `BUYER_COUNTRY_NAME` ,`SELLER_COUNTRY`.`NAME` as `SELLER_COUNTRY_NAME` ,`KYLIN_SALES`.`OPS_USER_ID` as `KYLIN_SALES_OPS_USER_ID` ,`KYLIN_SALES`.`OPS_REGION` as `KYLIN_SALES_OPS_REGION` ,`KYLIN_SALES`.`PRICE` as `KYLIN_SALES_PRICE` FROM `DEFAULT`.`KYLIN_SALES` as `KYLIN_SALES` INNER JOIN `DEFAULT`.`KYLIN_CAL_DT` as `KYLIN_CAL_DT` ON `KYLIN_SALES`.`PART_DT` = `KYLIN_CAL_DT`.`CAL_DT` INNER JOIN `DEFAULT`.`KYLIN_CATEGORY_GROUPINGS` as `KYLIN_CATEGORY_GROUPINGS` ON `KYLIN_SALES`.`LEAF_CATEG_ID` = `KYLIN_CATEGORY_GROUPINGS`.`LEAF_CATEG_ID` AND `KYLIN_SALES`.`LSTG_SITE_ID` = `KYLIN_CATEGORY_GROUPINGS`.`SITE_ID` INNER JOIN `DEFAULT`.`KYLIN_ACCOUNT` as `BUYER_ACCOUNT` ON `KYLIN_SALES`.`BUYER_ID` = `BUYER_ACCOUNT`.`ACCOUNT_ID` INNER JOIN `DEFAULT`.`KYLIN_ACCOUNT` as `SELLER_ACCOUNT` ON `KYLIN_SALES`.`SELLER_ID` = `SELLER_ACCOUNT`.`ACCOUNT_ID` INNER JOIN `DEFAULT`.`KYLIN_COUNTRY` as `BUYER_COUNTRY` ON `BUYER_ACCOUNT`.`ACCOUNT_COUNTRY` = `BUYER_COUNTRY`.`COUNTRY` INNER JOIN `DEFAULT`.`KYLIN_COUNTRY` as `SELLER_COUNTRY` ON `SELLER_ACCOUNT`.`ACCOUNT_COUNTRY` = `SELLER_COUNTRY`.`COUNTRY` WHERE 1=1 AND (`KYLIN_SALES`.`PART_DT` >= '2012-01-01' AND `KYLIN_SALES`.`PART_DT` < '2020-05-03'); |
3.3 从表中提取列值进行统计
这一步的任务类是SparkExecutable,其在执行时,实际上是通过命令行“spark-submit”提交Spark任务,对于该步骤,其命令部分如下所示:
|
1 |
/app/kylin/spark/bin/spark-submit --class org.apache.kylin.common.util.SparkEntry --name "Extract Fact Table Distinct Columns: kylin_sales_cube[20120101000000_20200503000000]" -className org.apache.kylin.engine.spark.SparkFactDistinct |
已省略掉命令中的conf、hiveTable、input、output等配置,从中可以看到,启动Spark任务的入口类是SparkEntry,其中会获取className传递的AbstractApplication实现类,通过反射生成实例,并执行其中的execute方法。
具体看一下SparkFactDistinct中的逻辑。首先从上一步的Hive表中读入数据。对每个分区下的所有数据,调用mapPatitionToPair方法,将分区中的数据一次性用FlatOutputFucntion类进行转化处理。再看一下FlatOutputFucntion中的具体转化逻辑,其实现了Spark的PairFlatMapFunction接口,在call方法中,首先检查是否已初始化,若未初始化,则执行初始化操作,初始化主要是从持久化存储中获取cube的元数据,并初始化一些计算器等,例如CuboidStatCalculator实例。然后在call方法中,对于读入的每一行,首先计算每行的字节数,然后加入全局累加器LongAccumulator中,用于统计上游源数据的字节数。对于每一行的每一列,若是字典列,则滤重并直接输出,而对于其他非字典类型的维度列,则更新其最大值和最小值,并维护在内存中。而对于每一行,会根据采样率(默认为1%)判断是否添加入CuboidStatCalculator实例中,而该计算器实例会采用HyperLogLog算法统计每个cuboid的基数值。在每个分区处理结束后,会输出每个cuboid的基数值。综上,经过第一步mapPatitionToPair,会输出3类值:
- 各cuboid的基数值;
- 字典列的滤重值;
- 维度非字典列的最大、最小值;
第二步调用repartitionAndSortWithinPartitions,通过分区器FactDistinctPartitioner将相同的key分配到同一个任务执行节点并排序,保证每个执行节点处理相同的数据,对于统计数据,则是同一个cuboid的数据,对于列数据,则是同一个列的数据。
第三步对于第二步重新分区的数据,仍调用mapPartitionsToPair将分区中的数据一次性用MultiOutputFunction类进行处理,
经过第三步处理,会输出以下文件,分别是:
- 字典列的滤重值;
- cube统计信息(每一个cuboid基于HyperLogLog算法的基数值);
- 维度列的最大和最小值;
3.4 基于Spark构建字典
这一步的任务类仍是SparkExecutable,实际执行逻辑在SparkBuildDictionary中,主要是进行字典的构建。
对于一些基数上限较小、取值长度变化的维度(比如地域),Kylin中可以选择字典类型,这样在构建时,Kylin会将此维度下的值构建成一张映射表,从而大大节约存储空间。
同时,Kylin支持对于复杂的count distinct度量进行字典构建,称为高级字典,以保证查询性能。目前Kylin提供两种字典格式,即global dictionary和segment dictionary。其中global Dictionary可以将一个非integer的值转化成integer值,以便bitmap进行去重。并且global dictionary会被所有的segment共享,因此支持跨segment的上卷去重操作。而segment dictionary虽然也是用于精确计算count distinct的字典,但与global dictionary不同的是,它是基于一个segment的值构建的,因此不支持跨segment的汇总计算。
另外,为了提升构建性能,可以将Hive中的维表设置为全局维表作为快照。Kylin为快照提供不同的存储类型,包括MetaStore和HBase两种。HBase是将维度表保存至HBase中单独的一张表,MetaStore是将维度表保存至元数据持久化的一个key上。
具体看一下SparkBuildDictionary中的逻辑。首先调用CubeDesc的getAllColumnsNeedDictionaryBuilt方法获取需要构建字典的列集合,包括采用字典编码的维度列、聚合函数中需要进行字典编码的列(例如TOPN函数)等。将这些列集合转化为JavaRDD<TblColRef>对象,并调用mapToPair通过DimensionDictsBuildFunction进行字典的构建。DimensionDictsBuildFunction中,首先通过getDistinctValuesFor方法从上一步生成的文件中读取相应字典列的值,然后在内存中将这些值构建成Dictionary接口实例。
Dictionary接口的实现有多个,若不指定,则根据维度类型和配置判断采用相应的实现,具体逻辑在DictionaryGenerator的newDictionaryBuilder(DataType dataType)中,对于date类型,使用DateStrDictionary,对于time类型,使用TimeStrDictionary,而对于其他类型,根据配置决定使用TrieDictionary或TrieDictionaryForest。
当构建完Dictionary接口实例后,字典元信息及其Dictionary接口实例会被持久化到元数据存储中,key的格式是“/dict/表名 /维度 /uuid.dict”,而value包含两部分,一部分是按JSON格式序列化的字典元信息,另一部分是按特定格式序列化的Dictionary接口实例信息。
在字典构建完成后,继续进行快照的构建。将维度集合转化为JavaRDD<DimensionDesc>对象,并调用mapToPair通过SnapshotBuildFunction进行快照的构建。这里只处理存储类型是“MetaStore”(非“HBase”)的快照。具体操作逻辑就是从Hive表中读取数据并保存到TrieDictionary实例中,然后和字典一样,持久化到元数据存储中。
在构建字典和快照后,会再将字典和快照信息更新到cube元数据的持久化存储中,便于后续查询时使用。
3.5 保存cuboid统计信息
这一步的任务类是SaveStatisticsStep,这里会将3.3中生成的各cuboid的基数统计值写入到持久化的元数据存储中,key的格式是“/cube_statistics/cube名称 /uuid.seq”。
利用这些信息,Kylin在这一步中还会进行两个优化:
- 通过decideCubingAlgorithm(cubingJob, newSegment)方法决定下一步如何构建cube。cube由多层cuboid构成,逐层减少维度,不断上卷,因此常规cube构建也可以分为多层,但这会导致当cube层数较高时,计算过程较长,且层与层之间涉及大量的IO操作,所以另一种构建方式是直接在mapper中进行cube构建,最后再合并,称为快速算法。这个优化在以MapReduce作为构建引擎时生效,而在Spark作为构建引擎时仍是采用分层算法。
- 通过optimizeCubingPlan(newSegment)进行剪枝,减少不必要的cuboid,这个优化后续专门列一章详细介绍。
3.6 创建HTable
这一步的任务类是HadoopShellExecutable,其获取参数HADOOP_SHELL_JOB_CLASS指定的Job Class并执行。这里的Job Class是CreateHTableJob,其调用HBase原生Client中HBaseAdmin的createTable(final HTableDescriptor desc, byte [][] splitKeys)方法创建HTable,并部署相应的查询协处理器。在创建前,Kylin会根据前述步骤产出的各cuboid统计值,预估整体HTable大小,并按照已设置的分区大小(默认是5G),计算出分区数,并进一步计算出分区的splitKeys。
3.7 基于Spark构建cube
这一步的任务类仍是SparkExecutable,实际执行逻辑在SparkCubingByLayer中,主要是进行cube的构建。
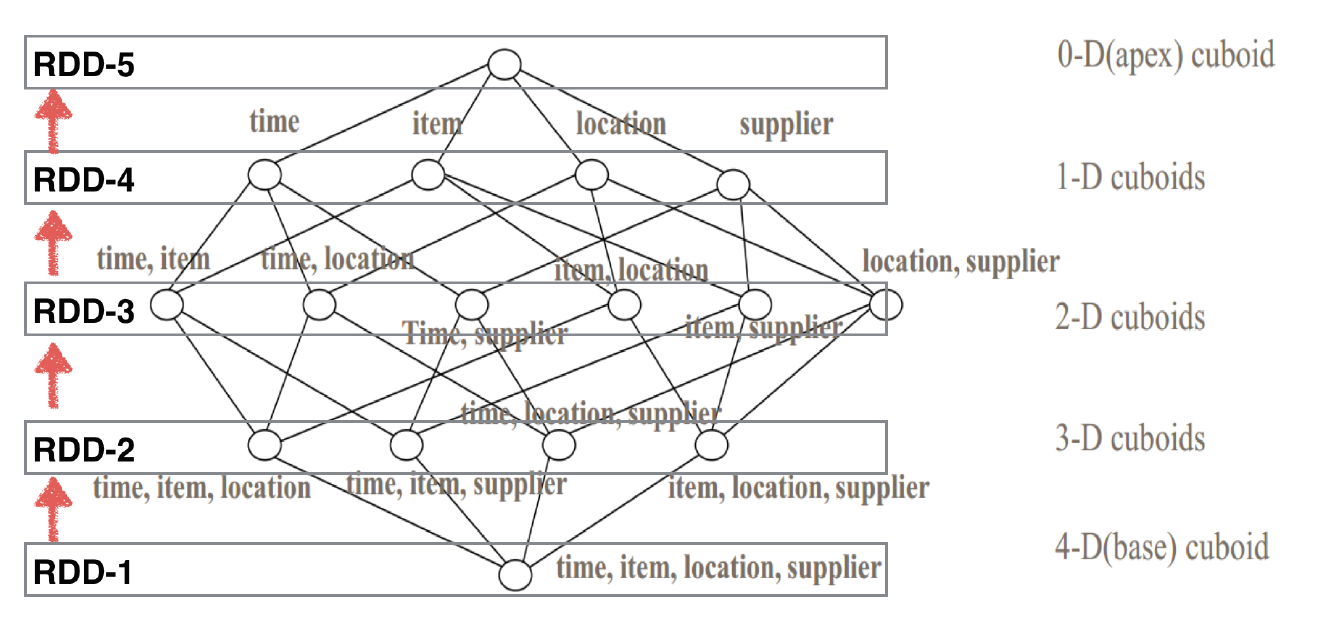
构建流程如图所示,采用的分层算法,逐层向上构建,每层的cuboid被抽象成Spark中的RDD,最下一层是base cuboid,即包含所有维度的聚合,逐层向上,选取一些维度上卷聚合,生成各层的cuboid,并把cuboid数据写入HDFS。核心代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// 聚合计算base cuboid allRDDs[0] = encodedBaseRDD.reduceByKey(baseCuboidReducerFunction, partition).persist(storageLevel); saveToHDFS(allRDDs[0], metaUrl, cubeName, cubeSegment, outputPath, 0, job, envConfig); PairFlatMapFunction flatMapFunction = new CuboidFlatMap(cubeName, segmentId, metaUrl, sConf); // 聚合生成ND cuboids for (level = 1; level <= totalLevels; level++) { partition = SparkUtil.estimateLayerPartitionNum(level, cubeStatsReader, envConfig); allRDDs[level] = allRDDs[level - 1].flatMapToPair(flatMapFunction).reduceByKey(reducerFunction2, partition) .persist(storageLevel); allRDDs[level - 1].unpersist(false); if (envConfig.isSparkSanityCheckEnabled() == true) { sanityCheck(allRDDs[level], totalCount, level, cubeStatsReader, countMeasureIndex); } saveToHDFS(allRDDs[level], metaUrl, cubeName, cubeSegment, outputPath, level, job, envConfig); } |
3.8 转化cuboid数据至HFile
这一步的任务类仍是SparkExecutable,实际执行逻辑在SparkCubeHFile中,主要是将cuboid数据转化为HFile,包括以下两步操作:
- 读取cuboid数据,不处理key(即维度),但对于value(即量度)根据cube的设置,转化为HBase中的列族。Kylin支持将不同的量度存储在不同的列族,这样主要是为了在查询时,减少扫描的数据量,加快查询速度。
- 完成上述转化后,Kylin会将转化的数据按key进行分区并调用Hadoop的API写入HDFS,核心代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 |
hfilerdd.repartitionAndSortWithinPartitions(new HFilePartitioner(keys), RowKeyWritable.RowKeyComparator.INSTANCE) .mapToPair(new PairFunction<Tuple2<RowKeyWritable, KeyValue>, ImmutableBytesWritable, KeyValue>() { @Override public Tuple2<ImmutableBytesWritable, KeyValue> call( Tuple2<RowKeyWritable, KeyValue> rowKeyWritableKeyValueTuple2) throws Exception { return new Tuple2<>(new ImmutableBytesWritable(rowKeyWritableKeyValueTuple2._2.getKey()), rowKeyWritableKeyValueTuple2._2); } }).saveAsNewAPIHadoopDataset(job.getConfiguration()); |
3.9 加载HFile至HBase表
这一步的任务类是HadoopShellExecutable,其Job Class是BulkLoadJob,其中使用了HBase原生支持的LoadIncrementalHFiles类以bulkload的方式将上步生成的HFile加载进HBase。
3.10 更新cube信息
这一步的任务类是UpdateCubeInfoAfterBuildStep,主要是将segment的状态更新为“Ready”,刷新缓存并通知查询引擎可扫描该segment。
3.11 清理Hive
这一步的任务类是GarbageCollectionStep,主要是删除Hive中的中间宽表和视图表。
3.12 清理HDFS
这一步的任务类是HDFSPathGarbageCollectionStep,主要是删除HDFS上的文件,包括生成的HFile、字典、列值等文件。
版权属于: 我爱我家
原文地址: http://magicwt.com/2020/06/28/kylin%e6%9e%84%e5%bb%ba%e6%ba%90%e7%a0%81%e5%88%86%e6%9e%90/
转载时必须以链接形式注明原始出处及本声明。