1-10 3,200 views
从14年5月至今,转眼一年多过去了,希望通过这篇文章对这段时间的主要工作做个简单的梳理、总结。
主要工作
搜狐公众平台(mp.sohu.com)是在搜狐门户改革背景下全新打造的分类内容的入驻、发布和分发全平台,通过搜狐网、手机搜狐网和搜狐新闻客户端三端来推广媒体和自媒体优质内容。搜狐公众平台主要流程如下图所示:

在整个流程中,我主要负责文章发文后的推荐工作,围绕文章推荐和流量分发,我主要完成了下述工作:
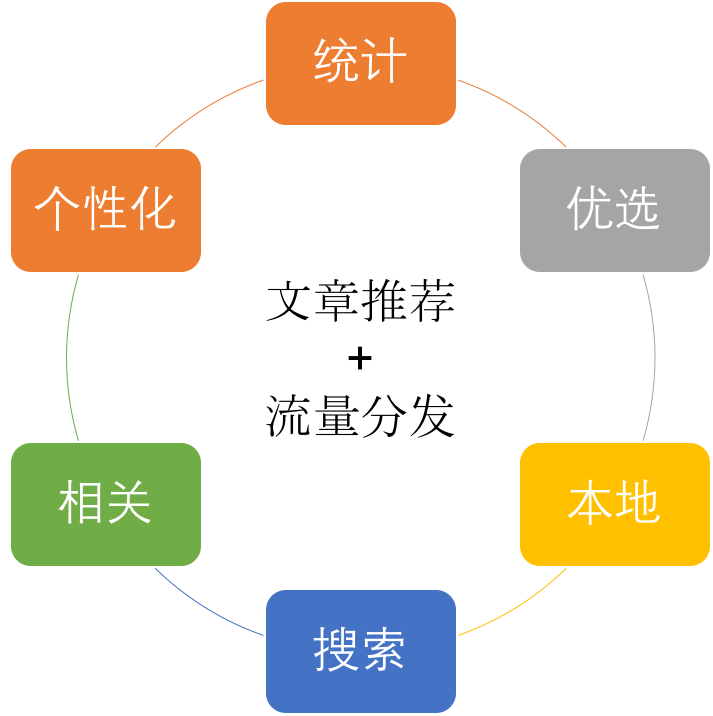
1)统计,对用户、文章流量进行离线、实时统计;
2)优选,对文章进行筛选、排序,选取优质内容自动更新至三端入口;
3)本地,对文章按地域进行归并,自动更新至客户端本地流;
4)搜索,对文章构建索引,提供按关键词进行文章搜索;
5)相关,计算文章之间的相关度,为每一篇文章提供相关文章列表;
6)个性化,计算文章和读者之间的相关度,通过“猜你喜欢”为读者提供个性化推荐文章列表。
技术架构
整体技术架构如下图所示:

1)接口接入,使用Nginx作反向代理,并基于OpenResty在Nginx中通过Lua读取数据实现高可用接口;
2)App,使用Java和Python作应用开发,Java应用基于Spring实现上下文管理、MVC和数据库读写等;
3)Web容器,使用Resin;
4)任务调度,使用Cronhub进行集中式管理;
5)日志收集,使用Flume读取Nginx日志并写入Kafka;
6)消息队列,使用Kafka;
7)数据计算,使用MapReduce作离线计算,使用Storm作实时计算;
8)数据存储,使用MySQL作关系存储,使用Redis/SSDB作Key-Value存储,使用HDFS/Hive存储海量日志数据;
9)搜索引擎,使用ElasticSearch搭建分布式高可用搜索集群。
具体实现
1)统计:
使用Nginx集群收集访问日志,使用HDFS存储访问数据,使用MapReduce离线处理访问数据,使用Flume+Kafka+Storm实时处理访问数据。通过离线和实时处理,统计平台流量数据。基于AngularJS+RESTful API实现内部数据运营系统。基于OpenResty实现高可用、高吞吐量的流量数据访问接口供前端页面调用。
2)优选:
基于流量反馈、作者平台表现、文章格式与时效选取优质文章作为热点推荐。
3)本地:
对平台海量文章基于地名关键词识别本地文章,并基于SimHash算法对文章按内容滤重。开发本地文章运营系统,对识别、滤重后的本地文章进一步人工筛选,提供本地文章接口供客户端调用展示。
4)搜索:
搭建Elasticsearch集群,对文章按照标题和内容构建索引,并对外提供文章搜索接口。
5)相关:
使用机器学习库Gensim库基于TF-IDF模型计算文章标题之间的相似度,选取相似度最高的若干篇文章作为相关文章,并对外提供相关文章接口。
6)个性化:
通过文章分类、关键词构建文章模型,使用Storm实时分析用户访问行为,通过其所访问文章的分类、关键词构建用户模型,计算用户模型与文章模型的余弦相似度,选取相似度最高的若干篇文章作为用户个性化推荐。
未来工作
未来计划深入算法方面的工作,搭建完整的算法开发框架,包括特征提取、离线训练、离线评测、模型上线、用户分桶、线上评测,目标是通过这套框架,使得算法开发流程规范化、流程化。

版权属于: 我爱我家
原文地址: http://magicwt.com/2016/01/10/%e5%b7%a5%e4%bd%9c%e6%80%bb%e7%bb%93/
转载时必须以链接形式注明原始出处及本声明。