10-01 5,790 views
Storm集群如图所示:
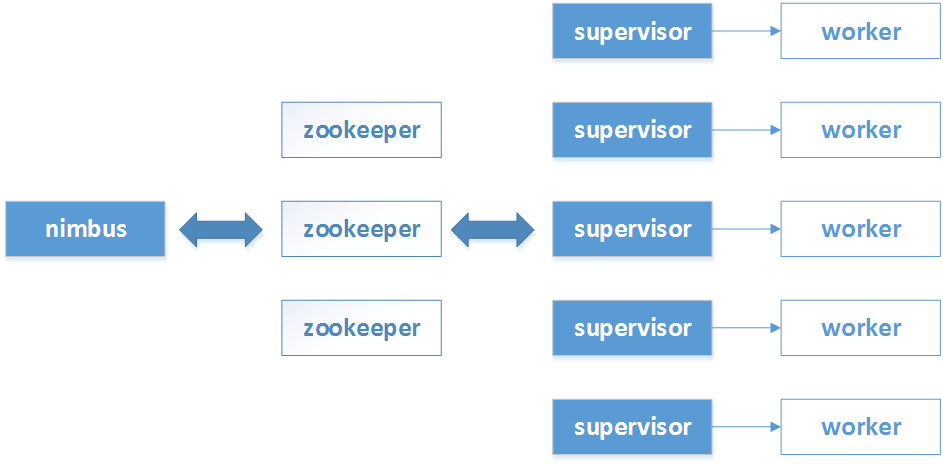
其中包含一个nimbus节点和多个supervisor节点:
1)nimbus,负责在集群中分发代码,分配计算任务,监控失败等;
2)supervisor,负责在集群中按照nimbus的分配,启动和停止计算任务;
3)worker,实际执行spout和bolt任务的进程;
在Storm安装目录下,可通过执行以下命令启动nimbus和supervisor进程(需先安装Python):
bin/storm nimbus|supervisor
nimbus和supervisor进程都是无状态和fail-fast的,状态保存在zookeeper和本地磁盘,当任何一个进程失败时,通过重启进程,可以快速恢复。Storm官方建议使用daemontools(http://cr.yp.to/daemontools.html)监控nimbus和supervisor进程,当有进程失败时,daemontools可以重启进程。
安装daemontools
摘自http://cr.yp.to/daemontools/install.html。
1)创建/package目录:
mkdir -p /package
chmod 1755 /package
cd /package
2)下载daemontools-0.76.tar.gz至/package,解压:
gunzip daemontools-0.76.tar
tar -xpf daemontools-0.76.tar
rm -f daemontools-0.76.tar
cd admin/daemontools-0.76
3)编译、启动daemontools:
package/install
daemontools会启动2个进程:
![]()
其中svscan默认扫描/service目录,可以在/service中配置需要监控的进程。daemontools使用supervise命令启动需要监控的进程,并在进程失败时,重启进程。
启动nimbus和supervisor进程
启动nimbus进程
在nimbus节点的/service目录,创建nimbus和ui子目录,并在nimbus和ui目录中分别创建名称为run的脚本。
nimbus目录中的run脚本为:
|
1 2 3 |
#!/bin/sh . /etc/profile /usr/local/bin/python2.7 /opt/software/storm/bin/storm nimbus |
ui目录中的run脚本为:
|
1 2 3 |
#!/bin/sh . /etc/profile /usr/local/bin/python2.7 /opt/software/storm/bin/storm ui |
run脚本其实就是使用storm命令启动nimbus和ui进程。
daemontools扫描到上述配置后,使用supervise命令执行run脚本,启动nimbus和ui进程:
![]()
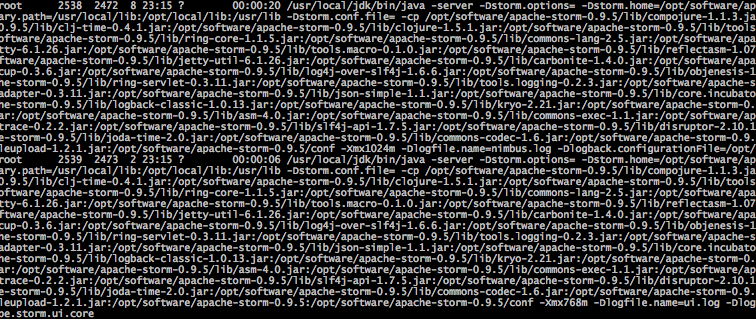
启动supervisor进程
与nimbus节点类似,在supervisor节点的/service目录,创建supervisor子目录,并在supervisor目录中创建名称为run的脚本:
|
1 2 3 |
#!/bin/sh . /etc/profile /usr/local/bin/python2.7 /opt/software/storm/bin/storm supervisor |
配置完成后,可以通过ui看到所有节点已启动:

版权属于: 我爱我家
转载时必须以链接形式注明原始出处及本声明。