8-15 3,362 views
什么是storm
- 分布式实时计算系统;
- 与hadoop为批处理提供map和reduce这两种操作原语类似,storm为实时处理也提供了spout和bolt这两种操作原语;
- storm的特点:
- 可扩展性,通过增加集群机器、调整计算并行度,即可以扩展计算性能;
- 保证数据不丢失,每条消息至少能被执行一次;
- 健壮性,集群状态保存在zookeeper中,节点不保存状态,节点故障不影响系统运行;
- 容错性,计算任务错误时,能够及时重新分配、运行计算任务,保证计算任务永远运行;
- 支持多种开发语言,java、python等。
storm的计算模型
- tuple,元组,strom中的数据模型,tuple由多个key-value组成;
- stream,流,多个tuple组成的序列,storm的计算过程就是输入流,对流进行转换、计算的过程;
- spout,输入流的操作;
- bolt,转换流的操作;
- topology,拓扑,由多个spout和bolt操作组成,实现某个具体计算任务。
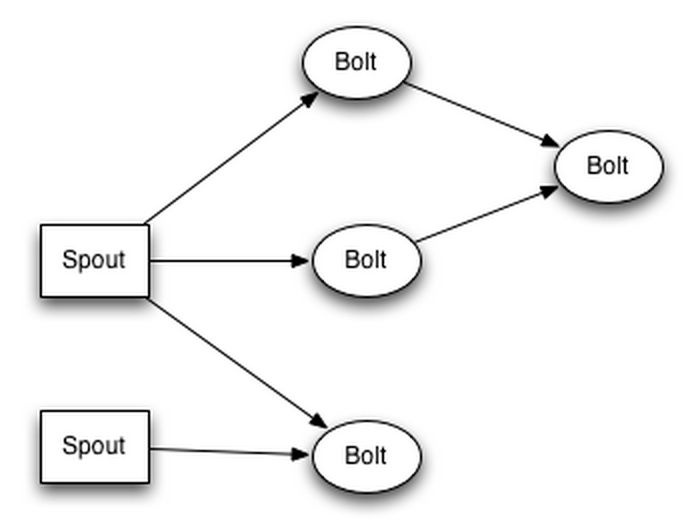
以word count为例,其spout生成sentence流,bolt 1接收sentence流,进行分词操作,生成word流,bolt 2接收word流,计算每个词出现的次数
storm的部署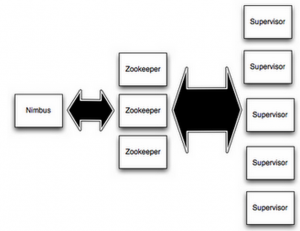
- 一个nimbus节点,多个supervisor节点,所有的节点都是fail-fast和无状态,状态保存在zookeeper和本地磁盘;
- nimbus,类似于hadoop中的JobTracker,负责在集群中分发代码,分配计算任务,监控失败等;
- supervisor,类似于hadoop中的的TaskTracker,负责在集群中按照nimbus的分配,启动和停止 计算任务。

通过storm提供的ui模块可以查看集群信息,从上述图中可以看出集群包含4个supervisor节点。
storm的api
- ISpout:
|
1 2 3 4 5 6 7 |
public interface ISpout extends Serializable { void open(Map conf, TopologyContext context, SpoutOutputCollector collector); //work进程初始化spout时运行该方法; void nextTuple(); //使用collector发送tuple; void ack(Object msgId); //某个tuple处理成功后,运行该方法; void fail(Object msgId); //某个tuple处理失败后,运行该方法; void close();//关闭spout时运行该方法 } |
- IBolt:
|
1 2 3 4 5 |
public interface IBolt extends Serializable { void prepare(Map stormConf, TopologyContext context, OutputCollector collector); //work进程初始化bolt时运行该方法; void execute(Tuple input);//处理tuple void cleanup();//关闭bolt时运行该方法 } |
- TopologyBuilder:
|
1 2 3 4 5 6 7 8 9 |
public class TopologyBuilder { public StormTopology createTopology() {…}//创建topology public BoltDeclarer setBolt(String id, IRichBolt bolt) {…}//设置bolt public BoltDeclarer setBolt(String id, IRichBolt bolt, Number parallelism_hint) {...} public BoltDeclarer setBolt(String id, IBasicBolt bolt) {...} public BoltDeclarer setBolt(String id, IBasicBolt bolt, Number parallelism_hint) {...} public SpoutDeclarer setSpout(String id, IRichSpout spout) {…}//设置spout public SpoutDeclarer setSpout(String id, IRichSpout spout, Number parallelism_hint) {...} } |
- StormSubmitter:
|
1 2 3 4 |
public class StormSubmitter { public static void submitTopology(String name, Map stormConf, StormTopology topology) throws AlreadyAliveException, InvalidTopologyException {…}//向集群中提交topology public static void submitTopology(String name, Map stormConf, StormTopology topology, SubmitOptions opts, ProgressListener progressListener) throws AlreadyAliveException, InvalidTopologyException {...} } |
- LocalCluster:
|
1 2 3 |
public class LocalCluster implements ILocalCluster { public void submitTopology(String var1, Map var2, StormTopology var3) {…}//在本地提交运行toplogy,多用于测试 } |
storm的数据可靠性
- 什么是storm的数据可靠性(数据完全被处理)?
仍以word count为例,spout从外部队列取消息生成sentence tuple,bolt 1生成word tuple,bolt2 生成word count tuple,这些tuple组成tuple树,sentence tuple是树的根节点。
当tuple树的所有叶子节点都被确认成功处理时,根节点才会被确认成功处理,这时可以向外部队列发送消息确认,否则会重新从外部队列获取消息再次处理。
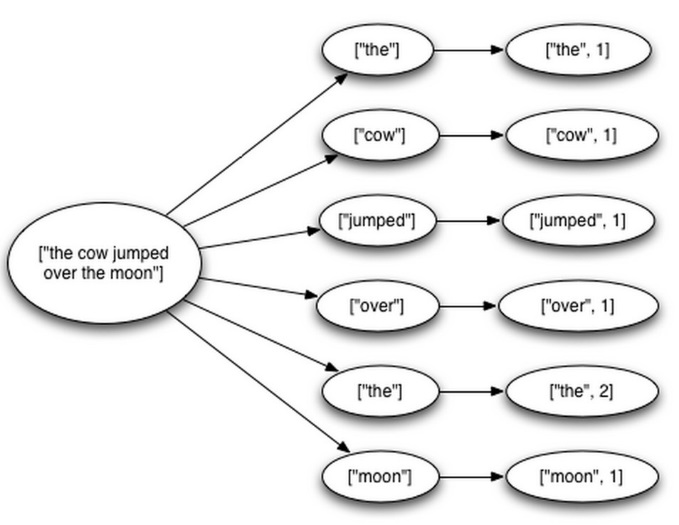
- 代码中如何保证数据可靠性?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public class SplitSentence extends BaseRichBolt { OutputCollector _collector; public void prepare(Map conf, TopologyContext context, OutputCollector collector) { _collector = collector; } public void execute(Tuple tuple) { String sentence = tuple.getString(0); for(String word: sentence.split(" ")) { _collector.emit(tuple, new Values(word));//发送新tuple } _collector.ack(tuple);//确认原tuple } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } } |
其中_collector.ack(tuple)用于确认输入tuple是否被正常处理。
- _collector.emit(oldTuple, newTuple)与_collector.emit(newTuple)的区别
前者会执行anchor操作,即在tuple树中构建oldTuple和newTuple的父子关系,newTuple及其后续tuple需要被确认成功处理,tuple树根节点才会被确认成功处理。
后者不会执行anchor操作,即在tuple树中只要oldTuple及其前续tuple被确认成功处理,tuple树根节点就会被确认成功处理,而不用监控后续tuple。
- 数据可靠性的实现原理
topology在负责spout和bolt的进程外,还有一个负责ack的进程,用于在emit和ack操作时,更新tuple树,ack进程确认tuple被成功处理是采用异或来实现的。
tuple1 xor tuple1 xor tuple2 xor tuple2 = 0
异或结果为0说明所有的tuple都被正常处理。
storm的并行计算
- 三类实体:
- worker:集群中的每台机器运行多个worker进程(默认值4);
- executor:每个worker processe进程运行多个executor线程;
- task:每个executor运行多个task(即spout和bolt)。
- 并行计算实例:

该topology由1个spout、2个bolt组成,需要设置blue-spout并行度为2,green-bolt并行度为2,yellow-bolt并行度为6,以下是在并行度配置代码:
|
1 2 3 4 5 6 |
Config conf = new Config(); conf.setNumWorkers(2); //使用两个worker进程运行topology topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); //使用2个executor线程运行blue-spout topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4).shuffleGrouping(“blue-spout”);//使用2个executor线程运行green-bolt,并使用4个task topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping(“green-bolt”);//使用6个executor线程运行yellow-bolt StormSubmitter.submitTopology("mytopology",conf,topologyBuilder.createTopology()); |
运行的进程、线程状态如图所示,共分配2个worker进程,10个executor线程,12个task,每个 进程各运行5个线程。

storm的分组策略
- shuffle grouping:随机分组;
- fields grouping:按字段分组;
- all grouping:广播分组,发送到bolt的所有task中;
- global grouping:发送到bolt的同一个task(task id最小)中;
- none grouping:同shuffle grouping;
- direct grouping:制定发送给某个task。
版权属于: 我爱我家
原文地址: http://magicwt.com/2015/08/15/storm%e8%af%bb%e4%b9%a6%e7%ac%94%e8%ae%b0/
转载时必须以链接形式注明原始出处及本声明。