6-09 3,118 views
Lucene是Apache基金会下的一个开源项目,提供能够实现全文索引和检索的Java API。Lucene包含索引引擎和检索引擎两部分。对于包含多个字段(Field)的文档(Document),可以通过Lucene的索引引擎对文档字段中的文本内容进行分词处理,构建关键字索引。当索引构建完成后,可以通过Lucene的检索引擎对特定字段进行基于关键字的查询。Lucene支持多种查询方式,包括模糊检索、分组查询等。对于查询结果,Lucene使用基于向量空间模型的排名算法计算得出查询结果的排名。
1.1 倒排索引
倒排索引(Inverted Index)是一种索引数据结构。在倒排索引中,词语被映射到包含该词语的文档。通过使用倒排索引,可以实现快速的全文搜索。一个简单的倒排索引及其构建过程如图1.1所示,其中文档d1和d2的内容分别是“home sales rise in July”和“increase in home sales in July”。
对于文档d1和d2,首先进行分词处理,将文本内容划分为词语集。因为在英文文本中,单词之间均有空格,所以使用空格作为分隔符进行分词处理,得到词语集,如图1.1中左侧一列。对于划分后的词语集,进行统计,统计词语及其出现的次数和位置,如图1.1中右侧一列,构成倒排索引。

图1.1 倒排索引及其构建过程
1.2 Lucene工作原理
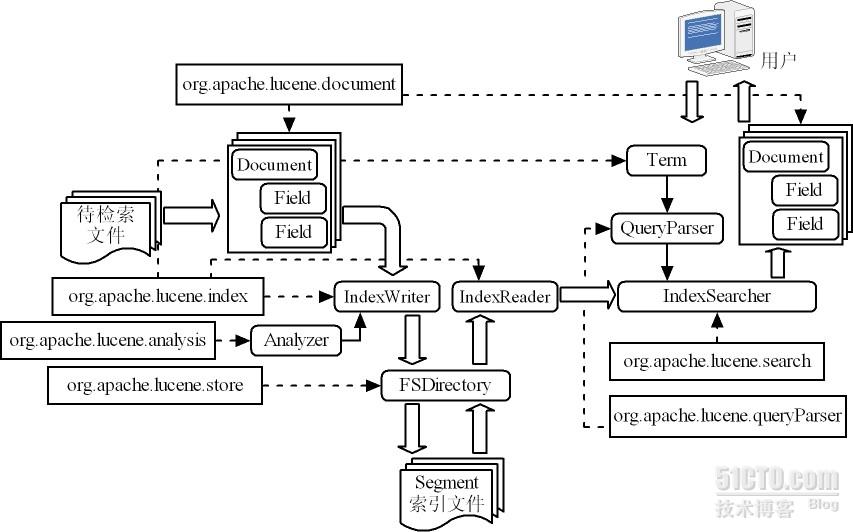
Lucene中包含了以下6个核心包:
1)org.apache.lucene.document包,包含了用于表示文档及其内容的类,如表示文档的Document类,表示文档中字段的Field类。
2)org.apache.lucene.index包,包含了用于构建、读取索引的类。
3)org.apache.lucene.analysis包,包含了用于对文档中的自然语言文本进行分词处理的类。
4)org.apache.lucene.store包,包含了用于存储索引的类。
5)org.apache.lucene.search包,包含了用于查询索引的类。
6)org.apache.lucene.queryParser包,包含了用于构建、解析查询条件的类。
在Lucene的倒排索引中,包含字段(Field)、文档(Document)、关键字(Term)这三个部分。每一个关键字均与一个集合相映射。集合中的每一个元素为一个二元组(Document,Field),表示该文档的该字段包含此关键字。Lucene的工作原理如图所示,主要分为以下6个步骤:
1)为每一个待检索的文件构建Document类对象,将文件中各部分内容作为Field类对象。
2)使用Analyzer类实现对文档中的自然语言文本进行分词处理,并使用IndexWriter类构建索引。
3)使用FSDirectory类设定索引存储的方式和位置,实现索引的存储。
4)使用IndexReader类读取索引。
5)使用Term类表示用户所查找的关键字以及关键字所在的字段,使用QueryParser类表示用户的查询条件。
6)使用IndexSearcher类检索索引,返回符合查询条件的Document类对象。
1.2 Lucene应用示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
package com.wt.testlucene.main; import java.io.File; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriter.MaxFieldLength; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.LockObtainFailedException; import org.apache.lucene.util.Version; public class TestLucene { private static final String indexDir = "J:\\tempIndex"; private static final String dataDir = "J:\\tempData"; public static void main(String[] args) throws CorruptIndexException, LockObtainFailedException, IOException, ParseException { /******************* 写入索引 *******************/ // IndexWriter用于写入索引 // FSDirectory表示索引存储于磁盘 // StandardAnalyzer表示采用标准的词法分析器进行分词处理 IndexWriter indexWriter = new IndexWriter(FSDirectory.open(new File( indexDir)), new StandardAnalyzer(Version.LUCENE_CURRENT), true, MaxFieldLength.UNLIMITED); indexWriter.setUseCompoundFile(false); File[] files = new File(dataDir).listFiles(); for (int i = 0; i < files.length; i++) { // Document表示索引中的文档 Document document = new Document(); // Field表示文档中的域,对于域有不同的处理方法 // Field.Store用于设置存储属性 // YES:存储 // NO :不存储 // Field.Index用于设置存储属性 // NO :不索引 // ANALYZED :索引且保存NORMS信息 // ANALYZED_NO_NORMS :索引但不保存NORMS信息 // NOT_ANALYZED :不索引但保存NORMS信息 // NOT_ANALYZED_NO_NORMS:不索引且不保存NORMS信息 // 存储name的域保存、索引但不分词 document.add(new Field("name", files[i].getName(), Field.Store.YES, Field.Index.NOT_ANALYZED)); // 存储content的域保存、索引且分词 document.add(new Field("content", new FileReader(files[i]))); // 存储path的域保存、不索引 document.add(new Field("path", files[i].getAbsolutePath(), Field.Store.YES, Field.Index.NO)); // 加入文档 indexWriter.addDocument(document); } // 优化 indexWriter.optimize(); // 提交 indexWriter.commit(); // 关闭 indexWriter.close(); /******************* 查询索引 *******************/ // IndexSearcher用于查询索引 IndexSearcher indexSearcher = new IndexSearcher(FSDirectory .open(new File(indexDir))); String queryString = "TEST"; // QueryParser用于解析查询语句生成相应的查询 QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "content", new StandardAnalyzer(Version.LUCENE_CURRENT)); Query query = parser.parse(queryString); // 返回最符合查询条件的前10个结果 TopDocs topDocs = indexSearcher.search(query, 10); ScoreDoc[] list = topDocs.scoreDocs; for (int i = 0; i < list.length; i++) { ScoreDoc scoreDoc = list[i]; Document document = indexSearcher.doc(scoreDoc.doc); // 输出文件序号、得分和名称 System.out.println(scoreDoc.doc + "\t" + scoreDoc.score + "\t" + document.get("name")); } indexSearcher.close(); } } |